Comparing the Quality of Structured Generation Engines
Executive summary
- Schema-compliance benchmarks like JSONSchemaBench are insufficient to assess the quality of a structured generation engine: an engine can seem perfectly compliant and still degrade the model's outputs.
- We propose a better methodology that compares engines' token masks to surface both over- and under-constraining errors. Across 5,047 schemas,
dotjsonrecords zero provable errors, whilexgrammarandllguidancemake millions. - These errors show up in accuracy. On BFCL tool calling,
dotjsonposts the best score on every model tested and systematically beats the unconstrained baseline.llguidanceandxgrammarcan fall below the baseline, hurting the model's performance.
Introduction
Structured generation engines constrain a model so its output conforms to a schema. On the surface they all make the same promise: valid, schema-compliant results. But implementing constrained generation correctly is genuinely hard, and not all engines deliver the same quality: they differ in how completely they enforce the schema and in how much the constraint ends up helping or hurting the model. Knowing which engine to trust therefore matters, and that's exactly what a benchmark should tell us. Yet benchmarking these engines is itself a difficult task. There are usually two different approaches, with two different goals.
One approach is to ask a model, constrained by the engine, to generate completions that satisfy the requirements expressed by JSON schemas. For that purpose, popular JSON Schema datasets such as JSONSchemaBench are often used. The engines are then evaluated on their ability to ensure the model returns a schema-compliant response, highlighting the advantage they provide over an unconstrained model that would sometimes violate the schema specifications. The main issue with that approach is that it does not measure what we really care about: semantic accuracy. What's the point of constraining a model if the responses provided are schema-compliant but wrong?
An alternative is to directly measure model accuracy with the structured generation engine and to compare it to an unconstrained baseline. A tree is recognized by its fruit: if the structured generation engine is of good quality, we will see a positive impact on accuracy. This is also the kind of evidence needed to address a recurring doubt, raised by several different papers, that constraining a model's output format degrades its accuracy. Measuring accuracy directly is the better approach, but it stumbles over the noise and nondeterminism of LLM text generation. You have to run many generations before seeing statistically significant results, and even then, so much depends on the JSON Schema dataset, the model, and the prompt. We can measure structured generation engines' performance for specific cases, but it's hard to generalize from there. Any benchmark results are open to accusations of cherry-picking.
Token Mask-Level Comparison
We are proposing a different approach here: assessing the validity of token masks at every step of a simulated generation. That allows us to isolate engines' action without the noise introduced by the model's generation and to analyze behavior over all tokens of the vocabulary, not just the single one sampled. Ideally, we would build an oracle based on a partial JSON Schema validator that would tell us for each token in the vocabulary whether a valid completion is possible if it were to be consumed. Then we would check that the engine's token mask agrees with it. However, there are two issues with that approach. First, building such an oracle is not easy at all. Putting aside tokenization issues, assessing what can be generated at each step to respect the JSON Schema is what engines do, so there's a bit of circularity going on. Second, even if we were to have such an oracle, we may run into scaling issues as evaluating hundreds of thousands of tokens at each generation step may require an infeasible amount of time and compute.
A practical workaround is to focus on the disagreements between the different engines. By doing so, we radically reduce the number of cases to analyze and have a lower bound on the number of errors associated with each engine. For each disagreement, we can determine what engine was right by walking down the index of the accepting engine until the completion is over. If the engine was correct to accept the token, then the resulting text produced should be valid according to the JSON Schema. If the value is invalid, then we consider the rejecting engine was correct.
Take this schema:
{
"type": "string",
"format": "date"
}
The following text has already been consumed by both engines A and B: "2026. At this point, the engines disagree on whether the token which decodes to / is allowed. We take the accepting engine, let's say A here, and we keep sampling tokens from its index until we reach the end of the generation. Let's say that in our case engine A generated "2026/05/26". All we have to do then is to use a JSON Schema validator to check whether the value respects the JSON Schema. Here it fails to validate: the date format requires hyphen-separated components (2026-05-26), so the slash makes the value invalid. We conclude that A wrongly allowed /, while B was correct to reject it.
There's an edge case though: the output might be invalid because of an error introduced later in the generation, not at the level of the disputed token. This is an acknowledged limit of the approach, although we should keep in mind that even in that case, we never inflate the total number of errors attributed to an engine: the false acceptance is misplaced within that same engine's tally, never reassigned to another one. The lower-bound property is preserved.
This approach has the valuable advantage of identifying both false acceptances and false rejections. The former corresponds to under-constraining and happens when the engine allows a token that would lead to an invalid completion. The latter corresponds to over-constraining and happens when the engine rejects a token that could lead to a valid completion. False acceptances are to some extent caught by the schema-compliance benchmarking method described earlier. False rejections are however much harder to identify as they are a type of silent error: they hurt model accuracy without you being able to easily see their action. Because the method we're proposing here allows us to identify false rejections as well as false acceptances, it gets to the heart of what explains structured engine performance.
Methodology
We compared the three leading constrained generation engines: llguidance (1.6.1), xgrammar (0.1.32), and dotjson (the JSON engine from .txt, v0.0.49). For schemas, we used the subset of JSONSchemaBench for which a valid test value exists in MaskBench, amounting to 5,047 schemas in total. Each MaskBench test value serves as the reference string for its associated schema. We traverse this string token by token: at each step we collect every token whose string representation is a valid next chunk of the remaining reference text, keep only those accepted by all engines, and pick one at random to append. We repeat until the reference string is fully consumed. Note that this means we only explore a single trajectory through each schema rather than the full space of valid completions: the error counts reported below are relative to these reference strings and to the tokens selected to represent them. A different set of either of those would surface a different set of disagreements.
All three engines are built from the same vocabulary, that of the tokenizer shipped with Qwen/Qwen2.5-7B-Instruct, so that their masks are directly comparable token for token. At each step of each schema, we collect the token mask from every engine. Then, we select only the tokens that fall outside the intersection of the three engines' masks. That typically leaves us with a small set per step, which is what makes this approach tractable. For each disagreement, we clone the internal state of every engine that accepted the disputed token and let it continue generating until completion, using a heuristic that favors JSON structural tokens (", }, ], etc.) to reach a terminal state as quickly as possible. This heuristic only affects speed, not the verdict: because the walk only ever samples tokens the engine itself allows, an invalid completion always proves a genuine false acceptance, and finding a single valid completion is enough to prove a false rejection. If the walk fails to terminate within 500 tokens, we simply skip the disagreement rather than guess at its verdict, in keeping with the goal of reporting a lower bound. The resulting completion is then validated against the schema using the Python jsonschema library, which tells us whether the disagreement was a false acceptance (completion is invalid) or a false rejection (completion is valid). Since jsonschema does not check format keywords on its own, we plug in dedicated validators for them, such as rfc3339-validator for date, date-time, and time.
To keep the comparison fair, we stop evaluating all engines on a given schema as soon as any one of them can no longer be assessed: either because it failed to compile the schema, or because it rejects every token needed to continue walking through the reference string. This ensures every engine is judged on the same set of decision points.
The output of the experiment is a list of false rejections and false acceptances for each of the three engines. Across all schemas this amounts to 431,966 positions at which the engines' masks are compared. At each position, every engine emits a mask over the full vocabulary, so the engines can disagree on many tokens at once. Since errors are counted per disputed token, a single position can contribute several. The counts reported below are therefore token-level error tallies, not position counts.
Results
Compilation
Before looking at the masking errors, we can look at compilation results, as they limit the number of schemas used for the analysis. The table below shows, out of the 5,047 schemas, how many each engine failed to compile.
| Engine | Rejections |
|---|---|
| dotjson | 403 |
| llguidance | 424 |
| xgrammar | 38 |
Compilation failures highlight the limits of each engine's supported features. This is acceptable when properly documented, though it still narrows what users can express. It's worth keeping in mind that rejecting a feature upfront is generally preferable to accepting it and producing silent errors during generation. This is something to bear in mind when reading the table above: xgrammar's low count partly reflects that it tends to compile some unsupported constraints rather than reject them, leaving them unenforced at generation time. As highlighted in this blog post, compilation does not certify all aspects of the schema will actually be enforced! Thus, the number above must be looked at along with the masking errors below.
Masking Errors
Before looking at the number of errors for each engine, we must distinguish between two types of "errors": bugs and features. In some cases, engines do decide to voluntarily depart from the JSON Schema specs when they consider end users are very unlikely to want full adherence. A good example of such departure concerns the email format. The JSON Schema specs allow a wide range of values, it's even possible to include comments within email addresses! In that case, engines make the reasonable choice to overconstrain to restrict the allowed patterns to standard email addresses users are likely to want.
On top of modifying some JSON Schema specs, an intentional form of "error" concerns elements specific to the quirks of generating text with an LLM. Some engines voluntarily exclude text strings that correspond to reserved tokens in the model's vocabulary to avoid parsing errors down the line. A last example we can mention is how llguidance uses a feature called fast-forward to save on the number of tokens generated by selecting a token without having the model generate anything.
All the "errors" we identified as features are excluded from the count below. We classified 3,364,811 disagreements as intentional features for dotjson, 3,549,667 for llguidance, and 5,064,714 for xgrammar.
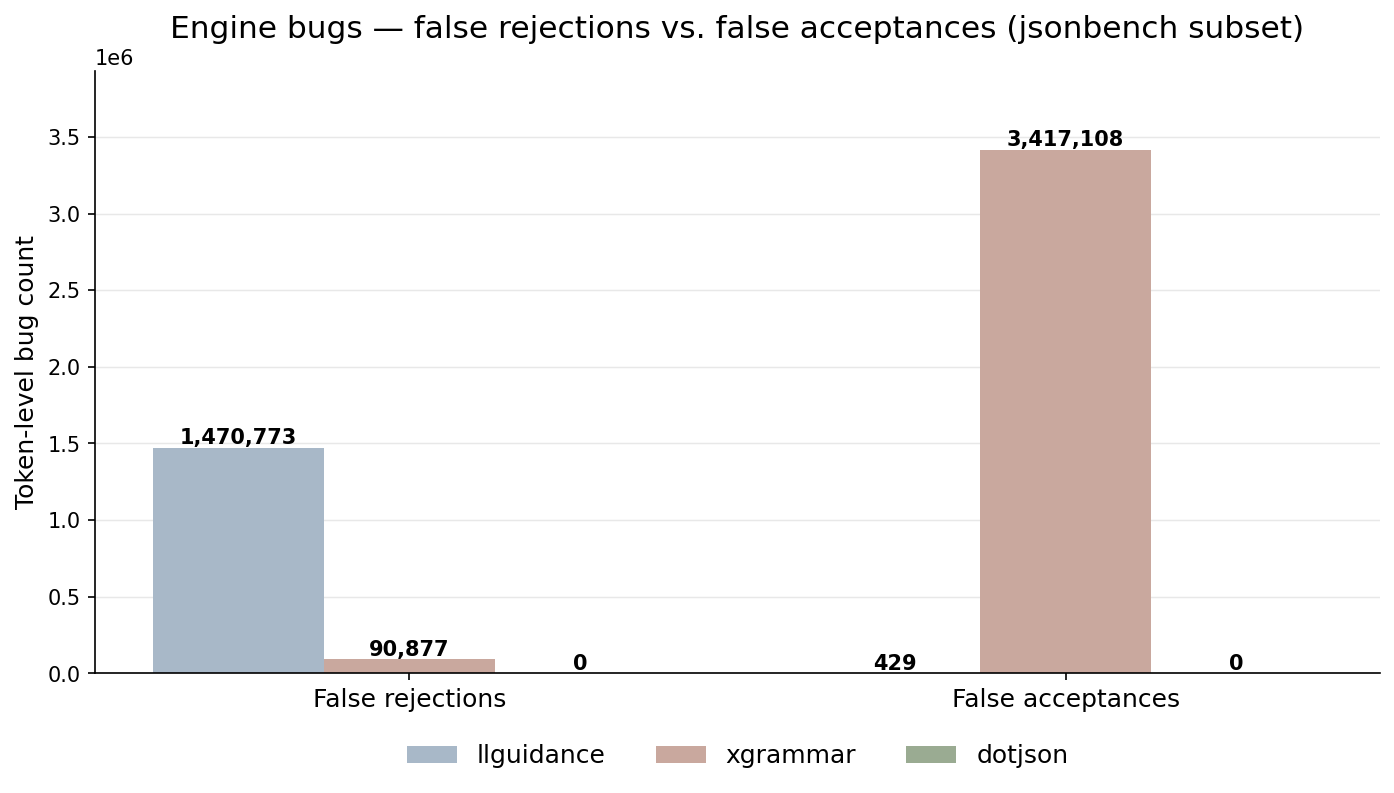
Figure 1: False rejections and false acceptances per engine, excluding intentional departures from the spec
With those intentional departures set aside, what remains are the genuine bugs, and here the engines diverge sharply. dotjson registers no provable errors at all, while the others reach into the millions: xgrammar accumulates 90,877 false rejections and llguidance 1,470,773. The picture is different for false acceptances, where dotjson is again at 0, but xgrammar reaches 3,417,108 while llguidance stays low at 429. A word of caution on these values: because the method only ever proves an error when a disagreement leads to a demonstrably invalid (or demonstrably valid) completion, the counts are a lower bound.
False acceptances correspond to under-constraining, meaning cases in which the engine did not implement the constraint: it did not add the expected guardrail and let the model behave as it would in the unconstrained situation. False rejections on the other hand correspond to over-constraining: preventing the generation of a token that would have been valid. The latter is particularly worrisome as it can degrade performance compared to the unconstrained baseline, as we will see in the next section.
Impact on Performance
As mentioned previously, engine errors only matter if they adversely impact accuracy, which is what we care about at the end of the day. On that matter, engine errors are not all made equal: for instance, the false rejection or acceptance of a very rare token in the vocabulary will most likely have a very limited adverse impact. On the other hand, wrongly rejecting a token that would probably have been sampled will lead to a serious degradation of accuracy.
To assess the severity of the errors identified above, we must come back to evaluating model accuracy with structured generation engines and compare them to the unconstrained baseline. This is where engines prove their quality. To do so, we ran evaluations using the live_multiple dataset of the BFCL benchmarks on tool calling with various models.
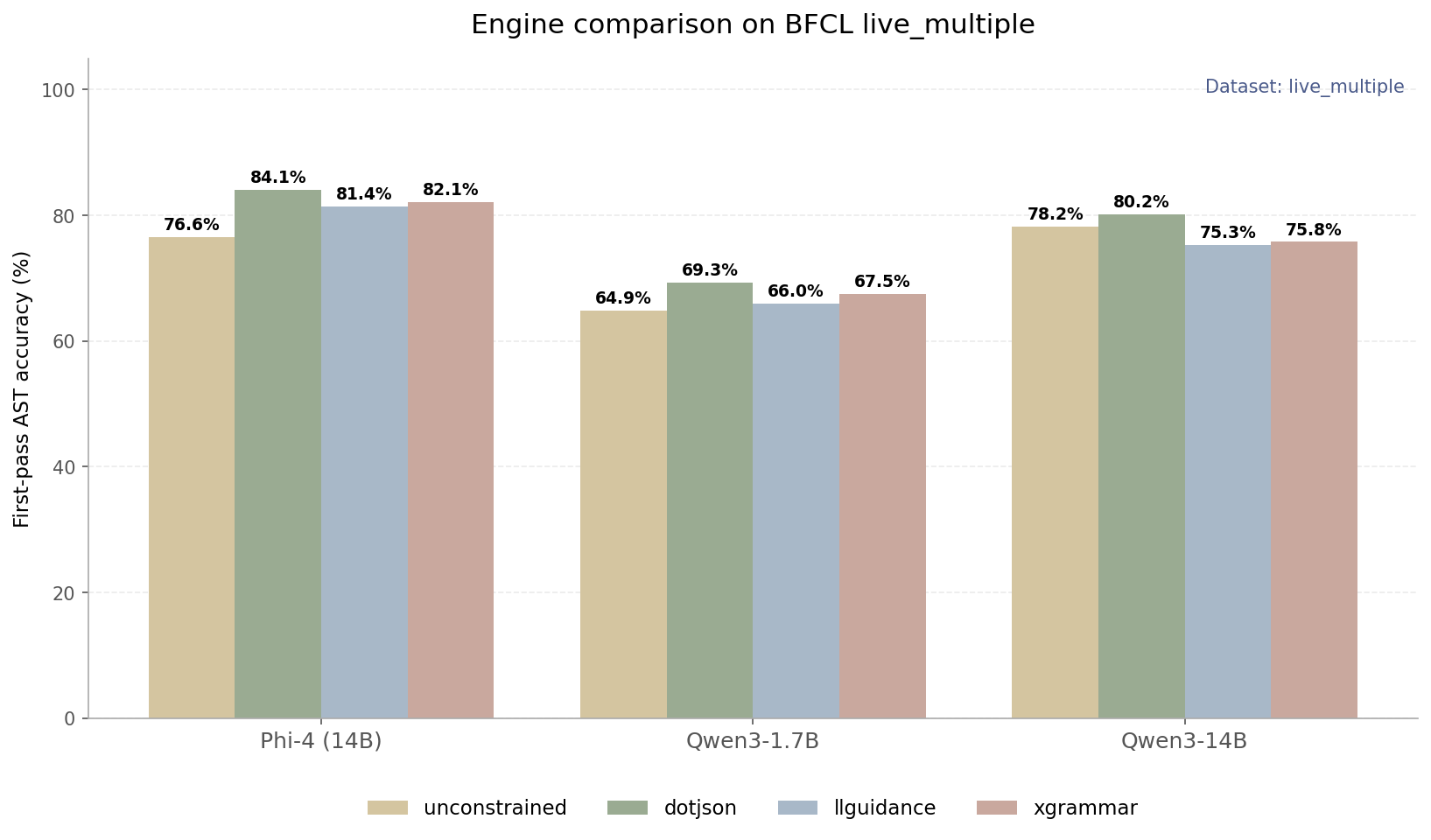
Figure 2: BFCL live_multiple accuracy across three constrained generation engines and an unconstrained baseline
This illustrates the impact of the token mask errors highlighted above: dotjson is ahead of its competitors for all models tested, posting the best constrained accuracy on Phi-4 (84.1%), Qwen3-1.7B (69.3%), and Qwen3-14B (80.2%). The contrast with the false-rejection counts is telling: on Qwen3-14B, both llguidance (75.3%) and xgrammar (75.8%) actually fall below the unconstrained baseline (78.2%), while dotjson (80.2%) improves on it. Over-constraining doesn't just fail to help, it can make the model worse than no constraints at all.
Conclusion
Implementing structured generation correctly is harder than it looks. The basic machinery may be straightforward enough to get right most of the time. But "most of the time" isn't the same as "always" and, for a layer that modifies the probability returned by the model, approximations can have serious consequences downstream.
A false rejection quietly removes a valid token from consideration, steering the model away from answers it would otherwise have found. A false acceptance lets an invalid token slip through, corrupting the output in ways the schema was supposed to prevent. Either way, the engine has failed its core promise: giving the model exactly the space it needs, no more and no less.
These errors impact generation. On Qwen3-14B, both llguidance and xgrammar fall below the unconstrained baseline; structured generation with those engines actively hurts the model. The engine meant to help is getting in the way. Our library dotjson, on the other hand, records zero provable false rejections and zero provable false acceptances across more than 5,000 schemas, and it shows: it posts the best constrained accuracy on every model tested.
An engine with errors defeats the purpose of structured generation. You reach for it to remove one source of uncertainty; a buggy engine replaces it with another. Delivering this promise means getting every mask right. It's a standard we do not compromise on.